
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- node.js
- 비지니스영어
- 머신러닝
- Oracle DB
- SAP ABAP
- nodejs
- 오라클
- 유럽여행
- 영어
- Spring Framework
- 자바
- Java
- IT
- oracle
- 딥러닝
- docker
- 도커
- 자바스크립트
- Mac
- JavaScript
- 노드
- sap mm
- SAP
- Python
- 오라클 디비
- SAP ERP
- ABAP
- Programming
- db
- 파이썬
Archives
- Today
- Total
JIHYUN JEONG
[Spotify Data Analysis/스포티파이 데이터 분석] AWS MySQL top tracks의 유사도 분석 (12) 본문
Data Science/Data Analysis
[Spotify Data Analysis/스포티파이 데이터 분석] AWS MySQL top tracks의 유사도 분석 (12)
StopHyun 2020. 3. 23. 22:55우선 related_artists 테이블 하나 만듭니다.

CREATE TABLE related_artists (artist_id VARCHAR(255), y_artist VARCHAR(255), distance FLOAT, PRIMARY KEY(artist_id, y_artist)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
만든 테이블에 top_tracks와 audio_features를 join 합니다. 조인한 다음 유클리드 거리를 구해서 곡의 유사도를 구분 합니다.
구분한 값들을 related_artists 테이블에 insert 합니다.
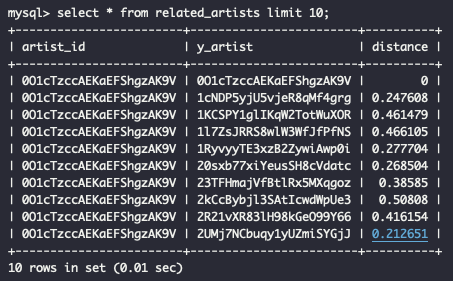
가장 유사도가 높은(유클리드 거리값이 적은) 상위 20개를 select 해봅니다.
select p1.name, p2.name, p1.url, p2.url, p2.distance from artists p1 join (select t1.name, t1.url, t2.y_artist, t2.distance from artists t1 join related_artists t2 on t2.artist_id = t1.id) p2 on p2.y_artist=p1.id where distance != 0 order by p2.distance asc limit 20;

'Data Science > Data Analysis' 카테고리의 다른 글
'Data Science/Data Analysis' Related Articles
more




Comments