
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 자바스크립트
- Oracle DB
- 도커
- SAP ABAP
- 오라클
- Mac
- JavaScript
- 비지니스영어
- 파이썬
- Java
- Spring Framework
- 자바
- SAP
- 영어
- sap mm
- IT
- nodejs
- db
- 머신러닝
- 딥러닝
- 유럽여행
- ABAP
- node.js
- oracle
- SAP ERP
- Python
- 오라클 디비
- 노드
- docker
- Programming
- Today
- Total
JIHYUN JEONG
[Spotify Data Analysis/스포티파이 데이터 분석] Zeppelin을 활용한 스파크(Spark), AWS S3, SQL (7) 본문
[Spotify Data Analysis/스포티파이 데이터 분석] Zeppelin을 활용한 스파크(Spark), AWS S3, SQL (7)
StopHyun 2020. 3. 19. 10:57제플린(Zeppelin)을 활용해서 Spark의 대한 기능들을 살펴보도록 하겠습니다.
기본적인 적들은 아래와 같은 구문을 통해서 활용할 수 있습니다.
스파크는 rdd라는 개념을 사용합니다.

AWS S3에 있는 parquet 데이터를 불러 올때는 아래와 같은 명령어를 통해 사용합니다. 스파크에서도 DataFrame 형식으로 데이터를 읽을 수 있습니다. 판다스의 DataFrame을 떠올리면 됩니다.
%pyspark
from datetime import datetime
raw = sqlContext.read.format("parquet").load("s3://spotify-data-artist/top-tracks/dt=2020-03-18/top-tracks.parquet")
# 일자별로 들어오게 할 경우
# raw = sqlContext.read.format("parquet").load("s3://spotify-data-artist/top-tracks/dt={}/top-tracks.parquet").format(datetime.now().date())
# print(type(raw))
raw.printSchema()
df = raw.toDF("artist_id", "external_url", "id", "name", "popularity", )
df.show()

Filter 기능을 이용해서 select의 여러 조건들을 사용할 수 있습니다.
%pyspark
raw = sqlContext.read.format("parquet").load("s3://spotify-data-artist/audio-features/dt=2020-03-18/top-tracks.parquet")
raw.printSchema()
df1 = raw.toDF("daceability", "energy", "key", "loudness", "mode", "speechiness", "acousticness", "instrumentalness", "liveness", "valence",
"tempo", "type", "id", "uri", "track_href", "analysis_url", "duration_ms", "time_signature")
# df1.show()
# select 구문
df2 = df1.select(df1['daceability'], df1['id'], df1['acousticness'])
# df2.show()
# filter 구문 / distinct()는 중복 제거
df3 = df2.filter((df2['daceability'] >= 0.30) & (df2['acousticness'] >= 0.1)).distinct()
df3.show()


스파크는 아래와 같은 방식으로 Function을 사용할 수 있습니다.
%pyspark
# spark 여러 functions
import pyspark.sql.functions as F
df_new = df1.select(df1['daceability'],df1['acousticness'], df1['liveness']).agg(F.avg(df1['daceability']).alias("avg_daceability"), F.max(df1['acousticness']).alias("max_acousticness"))
df_new.show()
또한 사용자가 정의한 함수들도 사용할 수 있습니다.
%pyspark
from pyspark.sql.functions import udf
from pyspark.sql.types import *
udf1 = udf(lambda e: e.upper())
# 사용자가 함수를 선언해서 사용
@udf(returnType=BooleanType())
def udf2(e):
if e >= 0.06:
return True
else:
return False
df_filtered = df1.filter(udf2(df1["daceability"]))
df_filtered.show()

%pyspark
artists = sqlContext.read.format("parquet").load("s3://spotify-data-artist/artists/dt=2020-03-18/artists.parquet")
artists.toDF("id", "name", "followers","popularity", "url", "image_url")
artists.show()
스파크에서 파이썬의 다른 외부 패키지를 사용하고 싶으면 AWS RMS 클러스터에 직접 접속해서 원하는 패키지를 설치해서 사용 할 수 있습니다.

Amazon EMR 클러스터 > 마스터 퍼블릭 DNS > SSH를 누르면 바로 접속 할 수 있는 마스터 노드 정보를 확인 할 수 있습니다.


설치를 할 때는 sudo pip install 원하는 모듈명 이런 방식으로 설치하면 됩니다.

pymysql 모듈이 설치 되었으면 AWS RDS(Mysql)에 바로 접근해서 원하는 정보를 가져와 보겠습니다.
아래 해당 정보는 본인의 정보를 입력하면 됩니다.
- host = "*"
- port = 3306
- username = "*"
- database = "*"
- password = "*"
%pyspark
import pandas as pd
import pymysql
host = "*"
port = 3306
username = "*"
database = "*"
password = "*"
try:
conn = pymysql.connect(host, user=username, password=password, db=database, port=port, use_unicode=True, charset='utf8')
cursor = conn.cursor()
except:
logging.error("error connection to RDS")
sys.exit(0)
# RDS - 아티스트 ID를 가져옴
cursor.execute("select * from artists limit 300")
colnames = [d[0] for d in cursor.description]
artists = [dict(zip(colnames, row)) for row in cursor.fetchall()]
df_artists = pd.DataFrame(artists)
# Pandas DataFrame
# df_artists.head()
# Spark DataFrame
spk_artists = sqlContext.createDataFrame(df_artists)
# spk_artists.show()
raw = sqlContext.read.format("parquet").load("s3://spotify-data-artist/top-tracks/dt=2020-03-18/top-tracks.parquet")
df_top_tracks = raw.toDF("artist_id", "external_url", "id", "name", "popularity")
# Column name 변경
df_top_tracks = df_top_tracks.withColumnRenamed("id", "track_id").withColumnRenamed("name", "track_name")
# Join(조인)
joined = spk_artists.join(df_top_tracks, df_top_tracks['artist_id'] == spk_artists['id'])
joined.show()
# SQL로 사용하고 싶다. temp table을 만든 것
joined.registerTempTable("joined")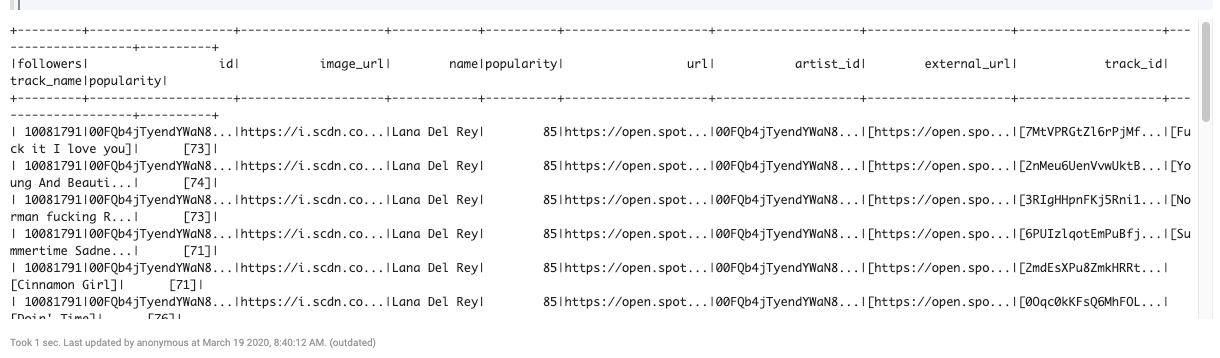
SQL로 바로 사용해 보고 싶은 경우 아래의 구문을 실행 후 쿼리를 실행합니다.
joined.registerTempTable("joined")
%sql
select id, name, track_name from joined LIMIT 10

audio-features 와 trop-track을 조인해서 데이터를 살펴보겠습니다.
%pyspark
import pandas as pd
import pymysql
host = "*"
port = 3306
username = "*"
database = "*"
password = "*"
try:
conn = pymysql.connect(host, user=username, password=password, db=database, port=port, use_unicode=True, charset='utf8')
cursor = conn.cursor()
except:
logging.error("error connection to RDS")
sys.exit(0)
# RDS - 아티스트 ID를 가져옴
cursor.execute("select * from artists limit 300")
colnames = [d[0] for d in cursor.description]
artists = [dict(zip(colnames, row)) for row in cursor.fetchall()]
df_artists = pd.DataFrame(artists)
# Pandas DataFrame
# df_artists.head()
# Spark DataFrame
spk_artists = sqlContext.createDataFrame(df_artists)
# spk_artists.show()
raw = sqlContext.read.format("parquet").load("s3://spotify-data-artist/top-tracks/dt=2020-03-18/top-tracks.parquet")
df_top_tracks = raw.toDF("artist_id", "external_url", "id", "name", "popularity")
# Column name 변경
df_top_tracks = df_top_tracks.withColumnRenamed("id", "track_id").withColumnRenamed("name", "track_name")
# Column select
df_top_tracks = df_top_tracks.select(df_top_tracks['track_id'][0].alias('track_id'), df_top_tracks['track_name'][0].alias('track_name'),
df_top_tracks['artist_id'], df_top_tracks['popularity'][0].alias('track_popularity'))
# Join(조인)
joined = spk_artists.join(df_top_tracks, df_top_tracks['artist_id'] == spk_artists['id'])
# joined.show()
# S3에서 불러오기
features = sqlContext.read.format("parquet").load("s3://spotify-data-artist/audio-features/dt=2020-03-18/top-tracks.parquet")
features.printSchema()
# DataFrame 형식으로
features = features.toDF("daceability", "energy", "key", "loudness", "mode", "speechiness", "acousticness", "instrumentalness", "liveness", "valence",
"tempo", "type", "id", "uri", "track_href", "analysis_url", "duration_ms", "time_signature")
features = features.withColumnRenamed("id", "track_id")
# # Join(조인)
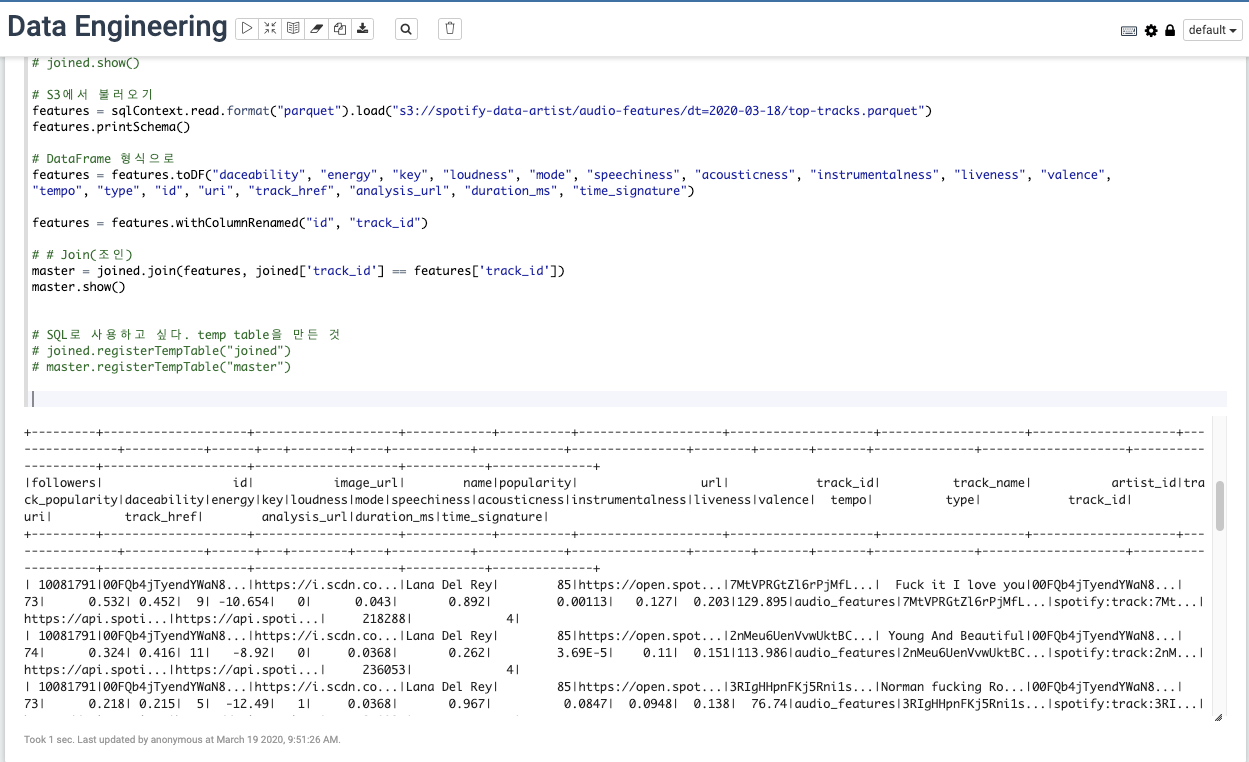
master = joined.join(features, joined['track_id'] == features['track_id'])
master.show()
# SQL로 사용하고 싶다. temp table을 만든 것
# joined.registerTempTable("joined")
# master.registerTempTable("master")
SQL을 활용해서 Track poppularity 와 artist popularity 간의 차이를 살펴보겠습니다. 또한, 특정 가수들은 어떤지 살펴보겠습니다. 인기도 순으로 보면 아래와 같은 결과로 나옵니다.
%sql
-- Track poppularity 와 artist popularity 간의 차이를 살펴봄
select name, popularity, avg(abs(popularity-track_popularity)) as diff from master group by 1,2 order by 3 asc limit 20
%sql
-- 유명한 가수들을 살펴보기
select name, popularity, avg(abs(popularity-track_popularity)) as diff from master where name IN ('BTS','Drake', 'Ed Sheerangroup', 'Ariana Grande', 'Rihanna') GROUP by 1,2 order by 3 asc limit 20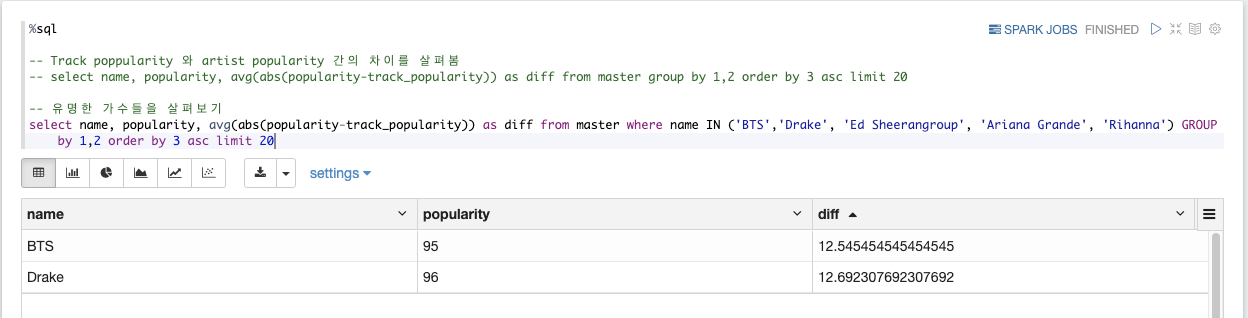
그리고 다음은 인기도의 분포를 살펴보겠습니다. 제플린의 좋은 점은 이렇게 시각화를 해서 볼 수 있습니다.
%sql
-- 인기도
select track_popularity, count(*) from master group by 1 order by 1 asc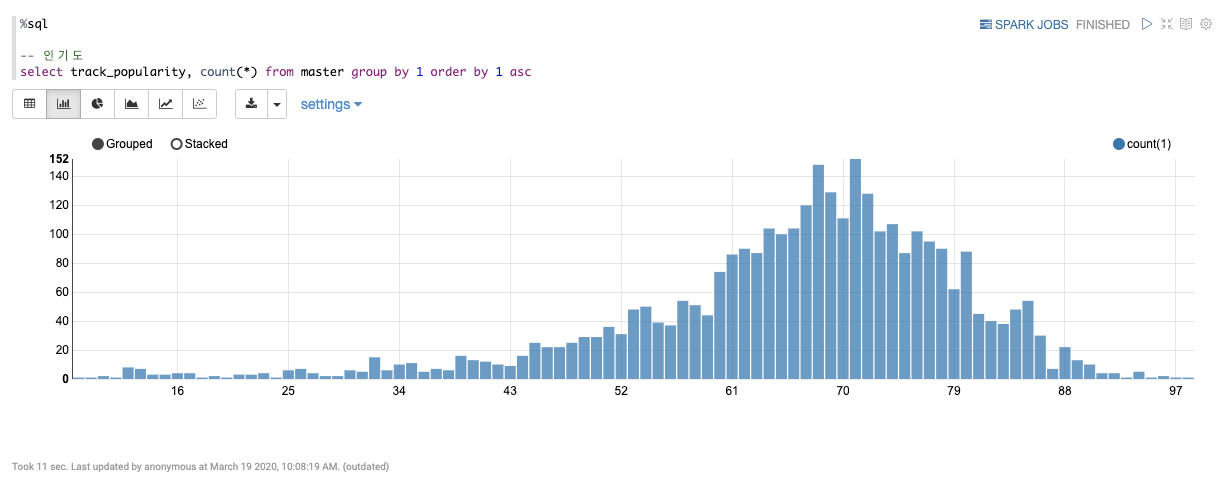
%sql
-- ("daceability", "energy", "key", "loudness", "mode", "speechiness", "acousticness", "instrumentalness", "liveness", "valence",
-- "tempo", "type", "id", "uri", "track_href", "analysis_url", "duration_ms", "time_signature")
-- 인기도가 80 이상인 애들의 Audio feature를 확인
select avg(acousticness), avg(liveness), avg(tempo) from master where popularity > ${popularity=80} and track_popularity > ${track_popularity=70}아래에서 ${} 이렇게 표시를 할 경우 쿼리 실행 후 해당하는 컬럼의 값들을 수정 할 수 있습니다.
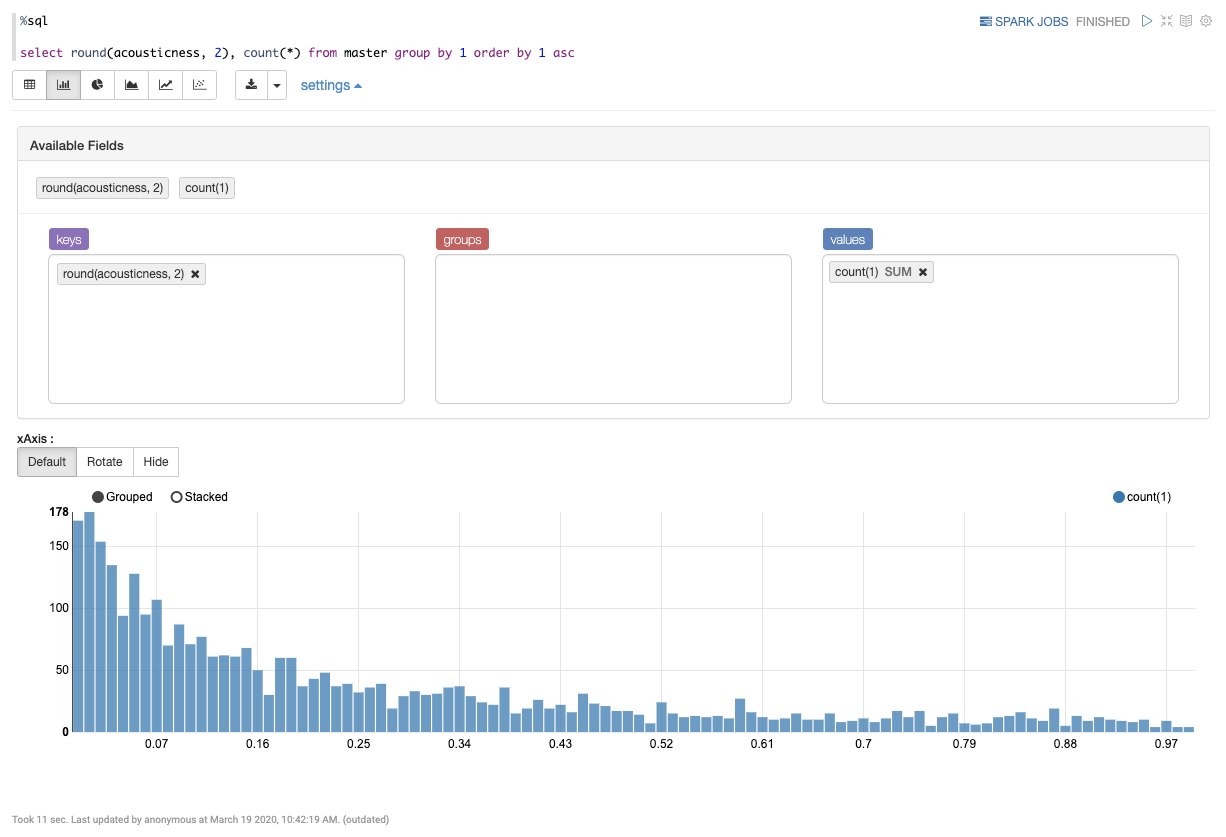
acousticness 측면에서 살펴본 결과 입니다.
%sql
select round(acousticness, 2), count(*) from master group by 1 order by 1 asc

daceability 측면에서 살펴본 결과 입니다.
%sql
select round(daceability, 2), count(*) from master group by 1 order by 1 asc
이상 제플린을 통해서 Spark를 활용하는 방법 SQL 쿼리, AWS S3에서 parquet 데이터를 가져오고 select, AWS RDS mysql에서 데이터를 select 해오는 것 까지 알아봤습니다.
스포티파이는 곡을 직접 올릴 수 있다고 합니다. 해당 곡들이 올라가면 여러 audio feature 들을 스포티파이에서 수치화를 하는데 가장 핫한 곡들의 여러 audio feature들을 참고해서 곡을 만든다면 좋은 결과가 나올 수 있지 않을 까 하는 생각을 해봅니다.
대한민국 만세!



